see also:
dynamics and numerics |
initial and boundary conditions |
physical parameterizations |
external parameters |
data assimilation
Last updated: September 2011
To meet the computational requirement of the model, the program has been coded in Standard Fortran 90 and parallelized using the MPI library for message passing on distributed memory machines. Thus it is portable and can run on any parallel machine providing MPI. Also it can still be executed on conventional scalar and vector computers where MPI is not available.
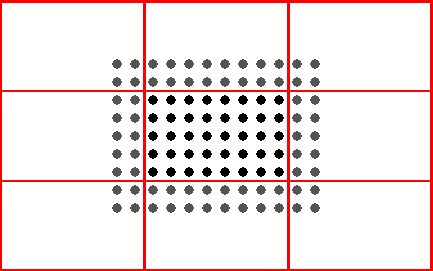
The parallelization strategy is the two dimensional domain decomposition which is well suited for grid point models using finite differences. Each processor gets an appropriate part of the data to solve the model equations on its own subdomain.
This subdomain is surrounded by 2 halo gridlines which belong to the neighboring processors. How many grid lines are taken as halo is configurable. The Leapfrog scheme needs 2 halo lines, while the Runge-Kutta scheme needs 3. During the integration step each processor updates the values of its local subdomain; grid points belonging to the halo are exchanged using explicit message passing. The number of processors in longitudinal and latitudinal direction can be specified by the user to fit optimal to the hardware architecture.